고정 헤더 영역
상세 컨텐츠
본문
결론부터 말하자면, python 에 설치하는 모듈로 원하는 *OCR 결과를 얻어오기는 어렵습니다.
* OCR: 광학 문자 인식(Optical Character Recognition)
easy ocr, pytesseract ocr 등 활용하여 python에서 OCR 해봤으나, 사용할만한 수준의 데이터를 얻어오기 어려워 다른 방법을 찾아냈습니다.

바로, 네이버 클로바 OCR 을 활용해서 텍스트를 엑셀로 변환하고, 엑셀을 pandas로 읽어 데이터 처리하는 방법입니다.

저의 경우, 스캔한 pdf 파일에서 텍스트 정리하는 업무에 활용하기 위해 OCR이 필요했고, 네이버 클로바 OCR을 활용한 결과는 만족스러웠습니다.
pdf 파일 이미지로 변환 ▶ 이미지 OCR 후 엑셀 저장 ▶ pandas로 데이터 처리 순서로 진행합니다.
1. pdf 파일 이미지로 변환하기
pip install PyMuPDFfolder_path = "C:\\Users\\Lenovo\\Desktop\\스캔pdf"
file_path = folder_path + "\\가나다라마바사.pdf"
import fitz
doc = fitz.open(file_path)
for i, page in enumerate(doc):
if i == 0: # 첫번째 페이지만 이미지로 변환하는 경우
img = page.get_pixmap()
img.save(f"{folder_path}/{i}.png")
folder 경로 및 file 경로는 상황에 맞게 설정하시면 되고,
첫 번째 페이지만 이미지로 변환하는 경우 i == 0 등의 조건을 활용하셔서 필요한 페이지만 이미지로 추출하시면 됩니다.

2. 네이버 클로바 OCR 가입 및 OCR 처리
가입한지 시간이 좀 지나서 정확하지는 않을 수 있지만 아래 순서대로 진행하시면 됩니다!
수정 필요한 부분 있으면 댓글 남겨주세요ㅠ
① https://www.ncloud.com/product/aiService/ocr 에서 이용 신청하기를 클릭 합니다.


② 회원가입 후, 결제수단 입력(OCR 월 100회 무료 이후 건당[텍스트만] 3원 청구) 해주시면 됩니다.

③ 도메인생성( https://console.ncloud.com/ocr/domain ) 까지 마무리 후
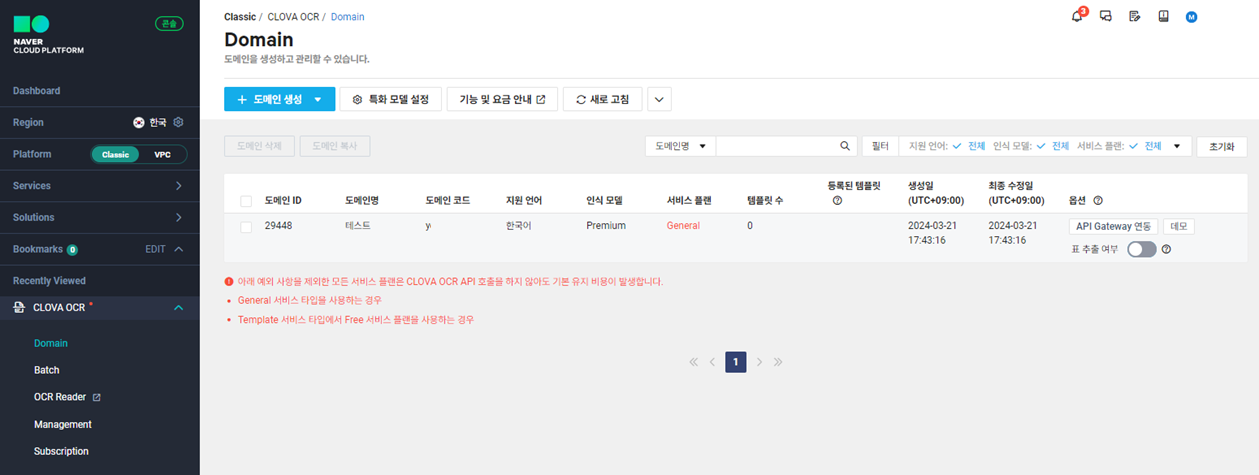
API 통해서 추출 결과를 전달 받을 수도 있는 것 같습니다.
④ OCR Reader 클릭 후 이미지 업로드

월 100회까지는 무료로 활용 가능합니다.
⑤ 텍스트 추출 결과
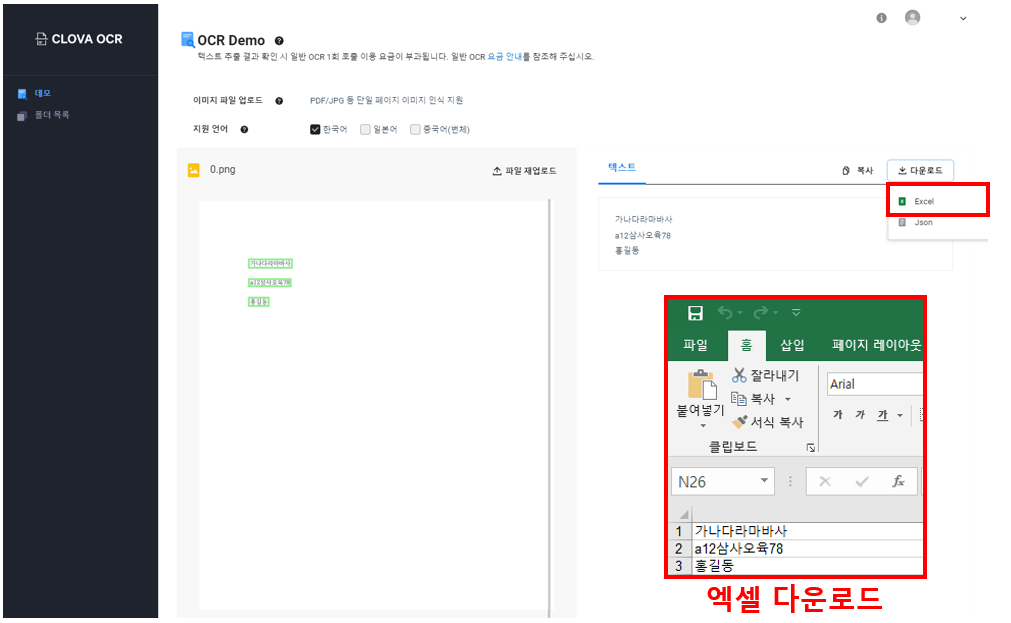
추출한 텍스트는 우측의 다운로드를 눌러서 엑셀로 받을 수 있고, 엑셀은 pandas 활용하여 데이터 처리가 가능합니다.
3. pandas로 데이터 처리하기
pandas에서 데이터 처리하는 방법은 아래 링크 참고 부탁드립니다.
[Pandas] pandas 설치 및 엑셀(excel) 데이터 처리 방법 소개
이번 글에서는 pandas 설치방법과 excel 데이터 처리 방법을 소개합니다. 1. Pandas 설치 및 업데이트 pip install pandas 터미널에 pip install pandas를 입력합니다. (Visual Studio Code에서 진행) 저의 경우, 이미 pa
real-bell.tistory.com
다만, 해당 엑셀 데이터들은 열 제목이 없기 때문에 아래와 같이 읽어오시면 됩니다.
# xls 파일이 있는 경로 내 모든 xls 파일들 읽어오기
files = glob.glob(f"{xls_file_path}/*.xls")
for file in files:
# 각 파일의 엑셀 pandas로 읽어오기
texts = pd.read_excel(file)
for i in texts.index:
# 열 제목이 따로 없기 때문에 아래와 같이 column[0]을 열 제목으로 설정
text = texts.at[i,f"{texts.columns[0]}"]4. 마치며
네이버 클로바 OCR 활용 시 100% 일치하는 결과를 얻을 수는 없었지만, 대부분 (95% 이상은 일치하는 느낌..?) 은 만족스러운 결과를 얻었습니다. 대기업 OCR .. 좋습니다.. ^^
'python' 카테고리의 다른 글
| [python] Chrome Webdriver 업데이트 없이 selenium(셀레니움) 실행하는 방법 (1) | 2024.04.28 |
|---|---|
| [Python] 내포 활용 예시(딕셔너리, 리스트, 정렬) (0) | 2022.08.07 |
| [Python] 리스트 평탄화 - 내포 활용 (0) | 2022.08.07 |
| [Python] 리스트 내포 if / else 구문 사용 방법 (0) | 2022.08.06 |
| [python] datetime (0) | 2022.06.02 |





댓글 영역